Quels types de bases de données ?
Quelles sont les différences entre Knowledge Base et RAG ?
Nous explorons ici deux technologies clés : Knowledge Base, ici uniquement le Knowledge Graph (1), alias base de données graphe ou GraphRAG, et RAG (Retrieval-Augmented Generation).

Note : Bien que Microsoft dispose d’une technologie « Open-Source » (2) appelée « GraphRAG », nous discutons ici du concept général de la combinaison des bases de données graphe et de la génération augmentée par récupération.
I. Contexte des technologies traitées
Pour clarifier, les deux technologies sont utilisées pour stocker des informations en vue d’une utilisation future.
Cela ne doit pas être confondu avec les instructions utilisateur, qui sont des données temporaires stockées pour maintenir le contexte au fil des interactions, permettant aux LLMs de créer une continuité conversationnelle. Dans le cadre du stockage non immédiat, l’objectif est de transformer des données brutes en données structurées pour une récupération efficace lors des inférences.
II. Mais quelle est la différence ?
Knowledge Graph
Un Knowledge Graph stocke et interroge les données en utilisant des structures de graphe où les nœuds représentent des entités et les arêtes représentent les relations.
Ces graphes excellent dans la capture des interrelations complexes au sein des données, permettant aux requêtes d’explorer ces connexions pour extraire des informations pertinentes et hautement contextualisées.
Forces : ils sont particulièrement efficaces pour représenter des données interconnectées, soutenir des requêtes complexes et permettre un raisonnement sur les relations au sein des données.
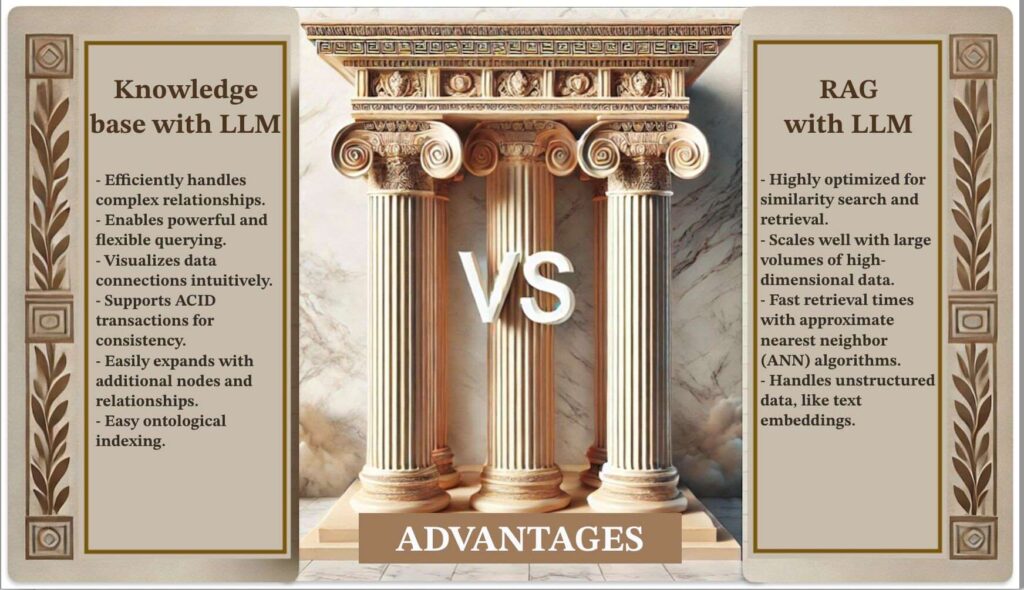
RAG combine la récupération d’informations avec la génération de texte en utilisant des modèles de langage. Il récupère des informations pertinentes à partir d’une base de données ou d’un index (généralement une base de données vectorielle dans des implémentations évolutives) et utilise ces informations pour générer des réponses enrichies de contexte.
Focus : Nous nous concentrons spécifiquement sur le RAG utilisant des bases de données vectorielles, car elles permettent une récupération efficace et évolutive des données pertinentes. Les implémentations RAG non basées sur des vecteurs (par exemple, utilisant des simples magasins de documents) peuvent ne pas bien évoluer et ne sont donc pas considérées ici.

III. Alors, laquelle est la meilleure ?
Comme toujours, la réponse dépend du contexte.
Chacune a ses forces selon le cas d’utilisation, la structure des données, et les besoins spécifiques de l’application. Dans certains cas, les deux peuvent être nécessaires.
Que le contexte soit avec vous.
(1) Uniquement le graphe, car c’est le meilleur moyen d’extraire des corrélations et de créer des relations à partir de données brutes.
(2) from langchain_openai import chat chatopenAI, « open source » disent-ils. Pour des raisons évidentes de confidentialité, je ne recommande pas d’utiliser cette technologie.