L’intelligence artificielle et le reinforcement learning
Il y a cinq mois, nous avons créé le système de Reinforcement Learning Monitoring Feedback (RLMF) pour Aurélia AI, l’IA qui rédige nos e-mails de prospection.
I. Concept de l’IA Aurélia
Le concept est simple : en vente, vous souhaitez envoyer le meilleur e-mail possible à votre public cible. Cependant, il est difficile de savoir à l’avance quel est le meilleur e-mail.
Par exemple, même si vous passez des heures à chercher sur Internet pour rédiger l’icebreaker personnalisé parfait pour une personne spécifique, il y a encore une probabilité considérable que votre e-mail finisse à la poubelle (bien sûr, Aurélia fait le travail à votre place, c’est le but).
II. Reinforcement Learning Monitoring Feedback (RLMF) pour l’automatisation
C’est ici que le test A/B entre en jeu. En testant une combinaison de centaines de modèles d’e-mails, chacun personnalisé pour le destinataire, vous pouvez déterminer le plus efficace. En Data Science, le système qu’on a créé est le Reinforcement Learning Monitoring Feedback (RLMF), qui utilise la pondération pour déterminer l’importance de chaque modèle d’e-mail pour chaque persona.
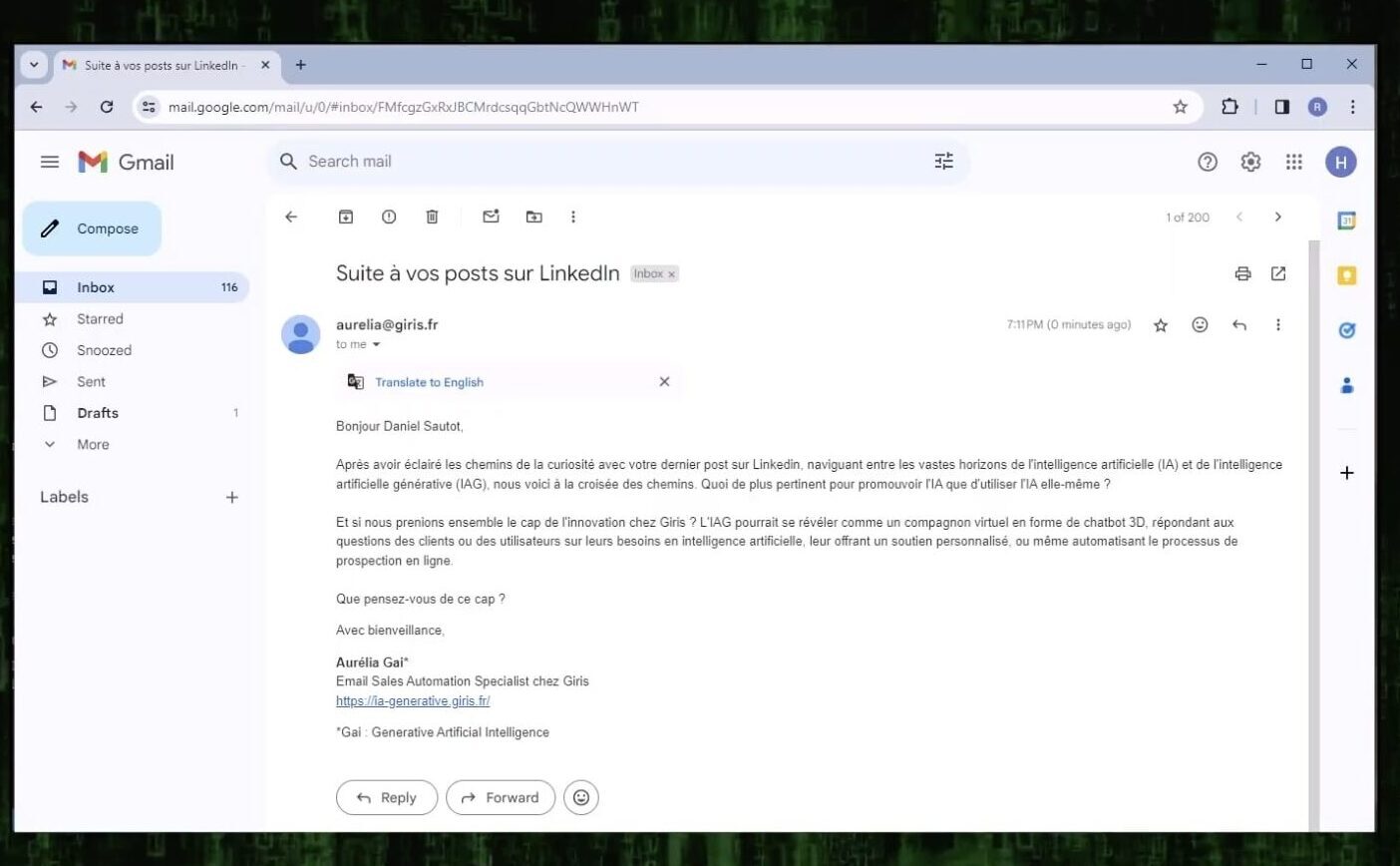
Nous sélectionnons le meilleur e-mail pour un persona particulier et améliorons continuellement le modèle. Au fil du temps, l’IA sera capable d’envoyer les e-mails les plus réussis pour chaque persona.
III. Comparaison avec ORP
Aujourd’hui, nous avons découvert un article intitulé « ORPO » qui décrit une approche similaire. L’algorithme ORPO souligne le rôle crucial du Supervised Fine-Tuning (SFT) dans l’alignement des préférences, mettant en avant qu’une pénalité mineure pour les styles de génération non favorisés est suffisante pour atteindre un SFT aligné avec les préférences.
ORPO introduit une approche novatrice, sans modèle de référence, appelée optimisation du rapport de cotes de préférence (équivalent à notre pondération), qui aligne efficacement les modèles sans nécessiter une phase d’alignement des préférences supplémentaire. Cette méthode pénalise les styles de génération indésirables et fournit des signaux d’adaptation forts pour les réponses préférées. Les résultats empiriques et théoriques de ORPO démontrent son efficacité à surpasser les modèles les plus avancés dans diverses évaluations, prouvant son potentiel à combiner le Supervised Fine-Tuning avec les techniques de Reinforcement Learning pour une performance optimale.