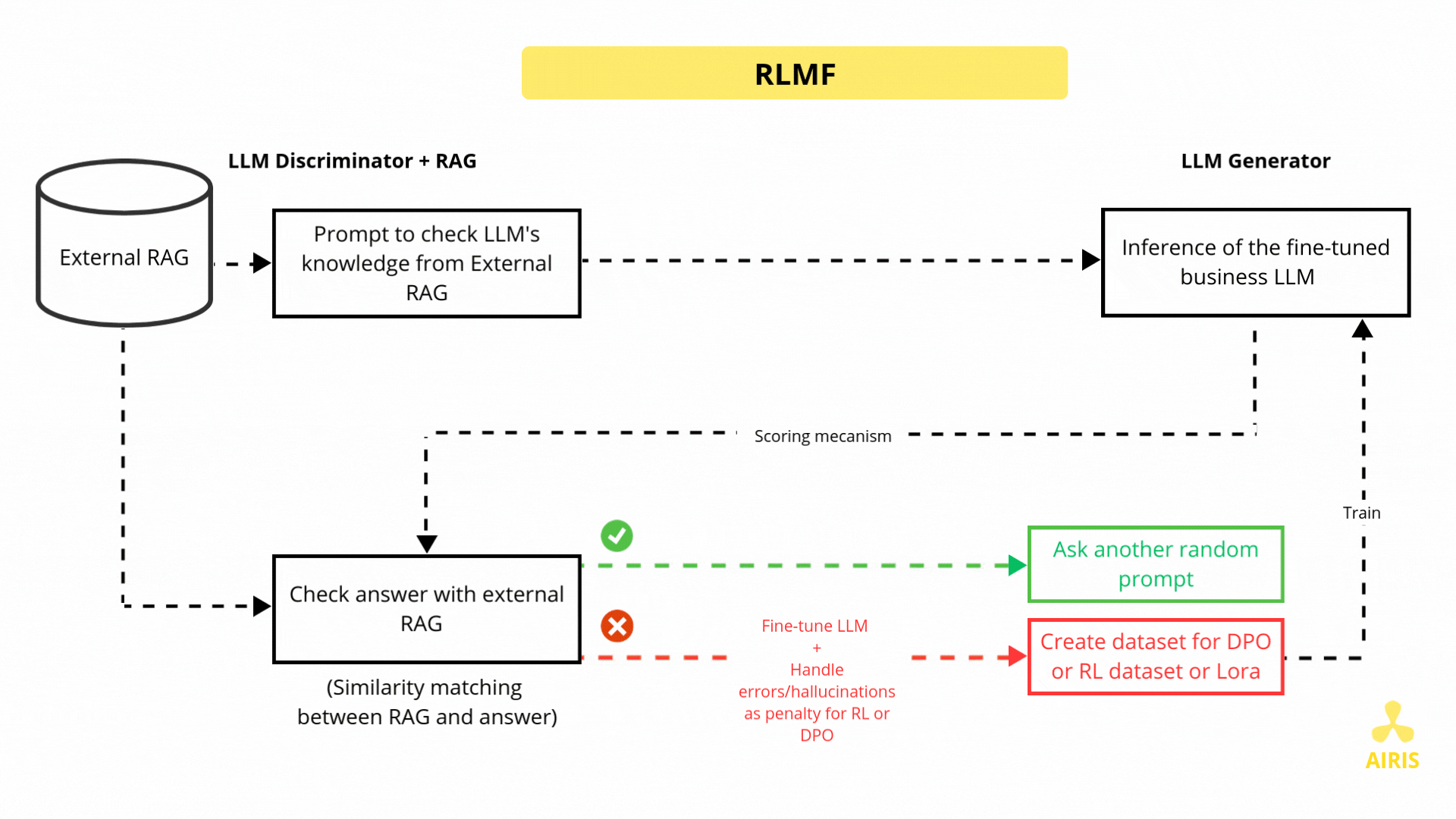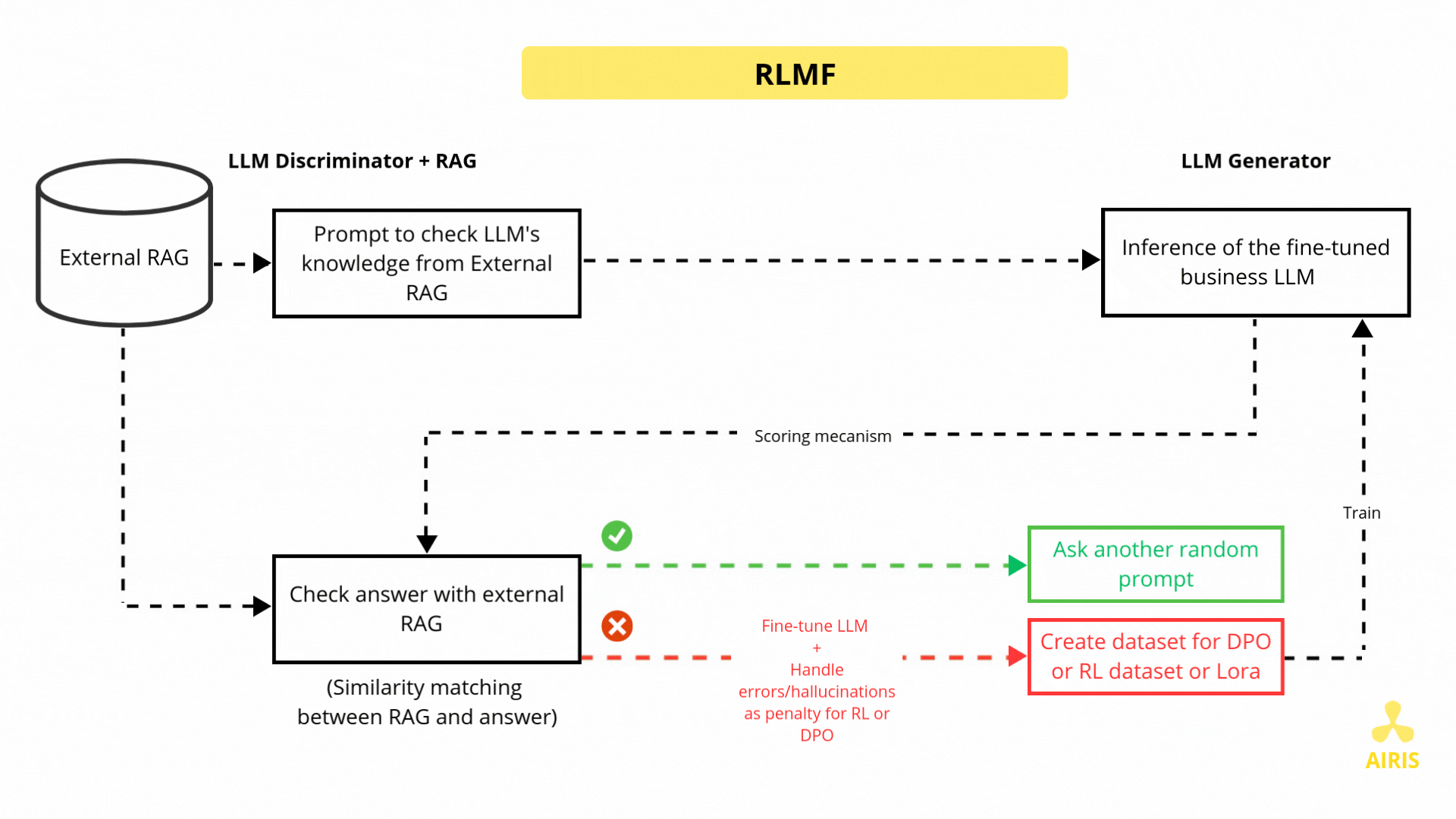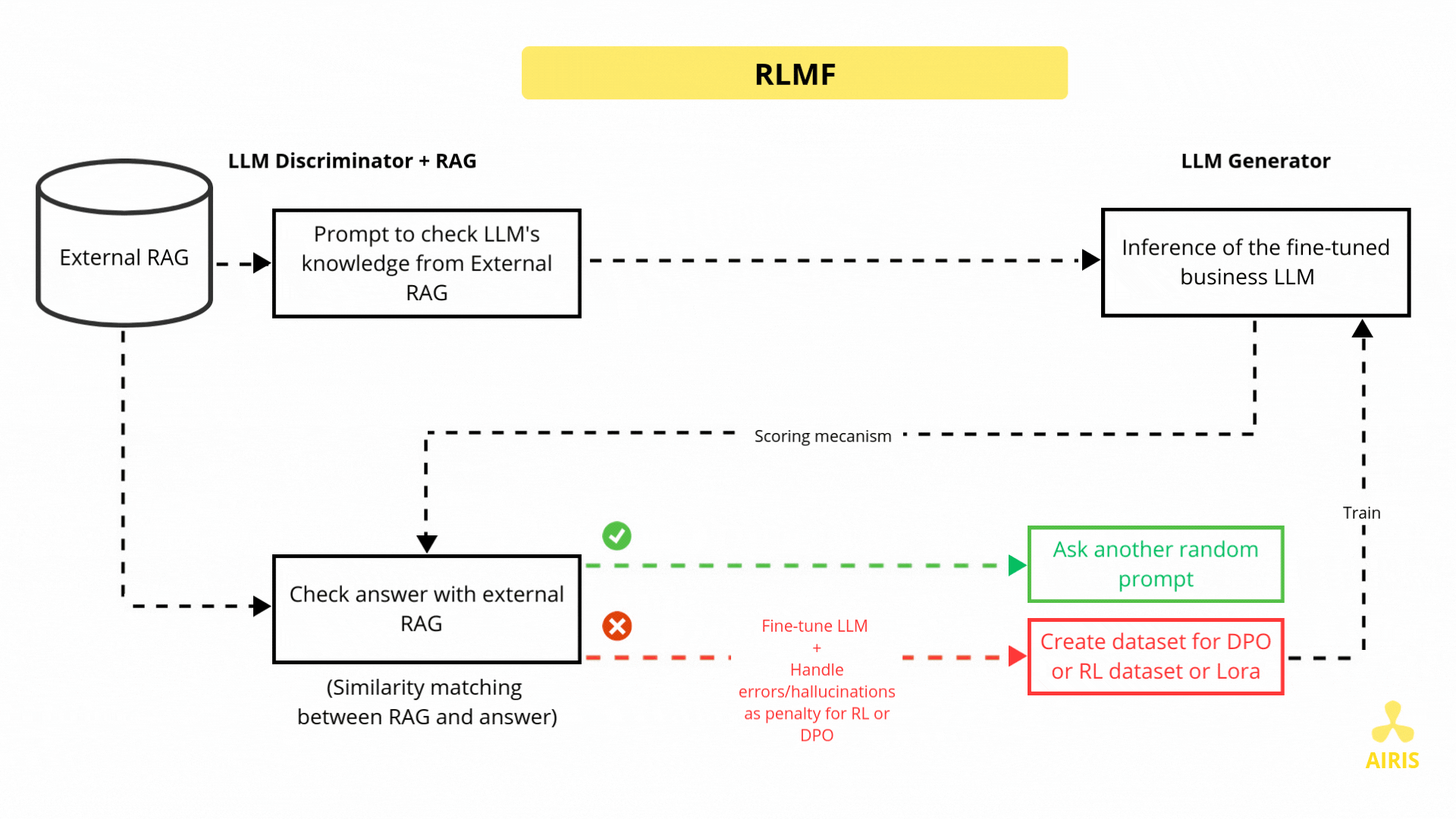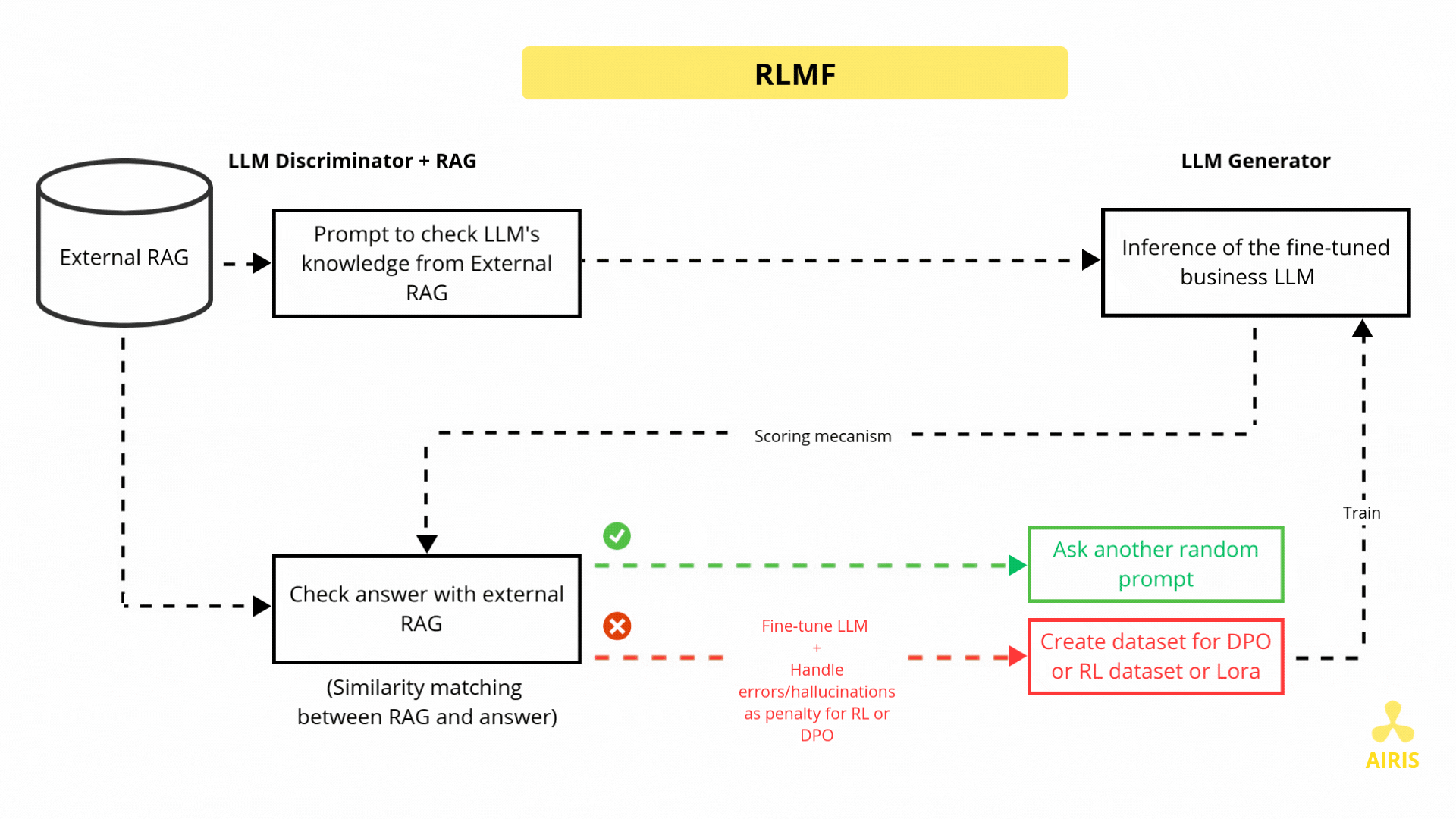
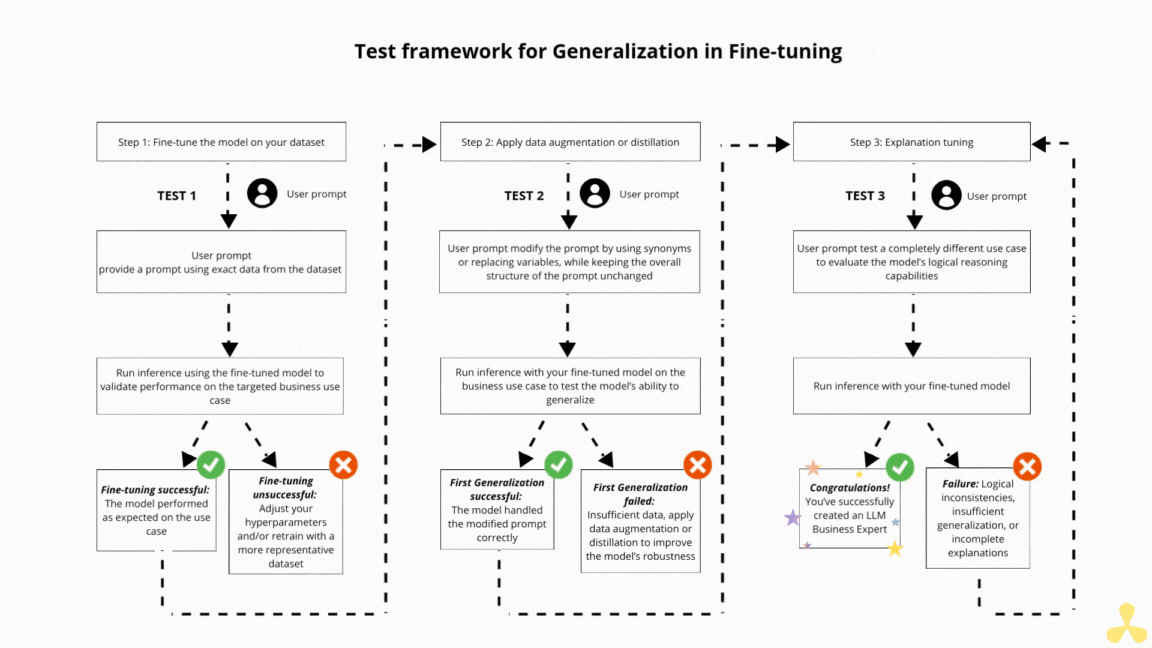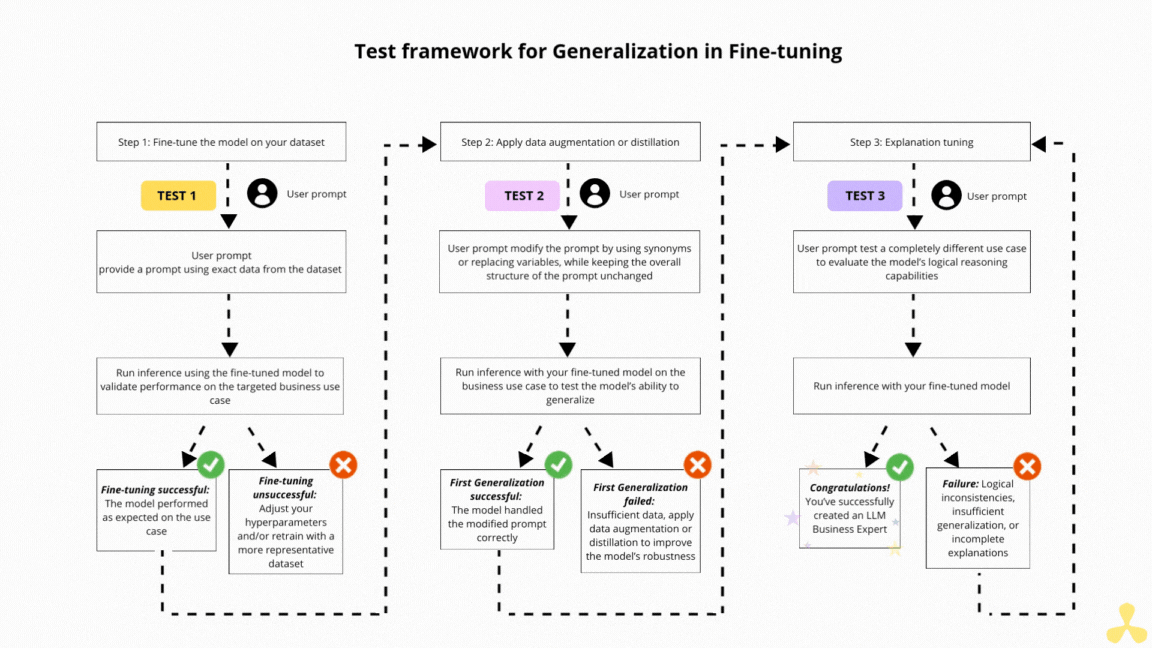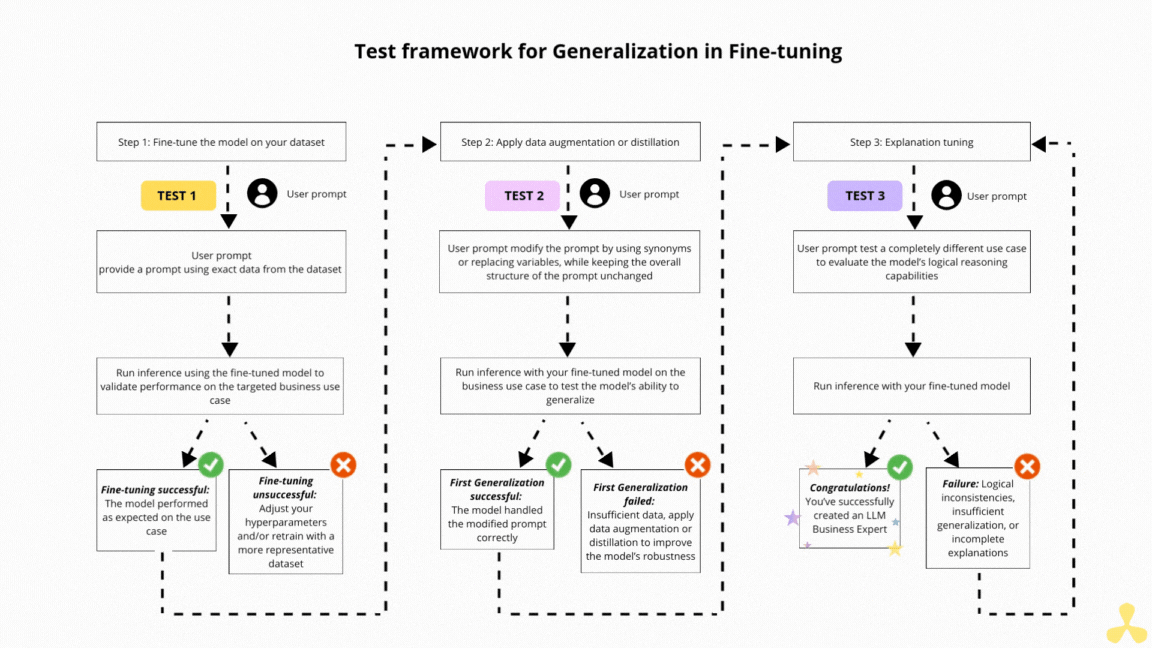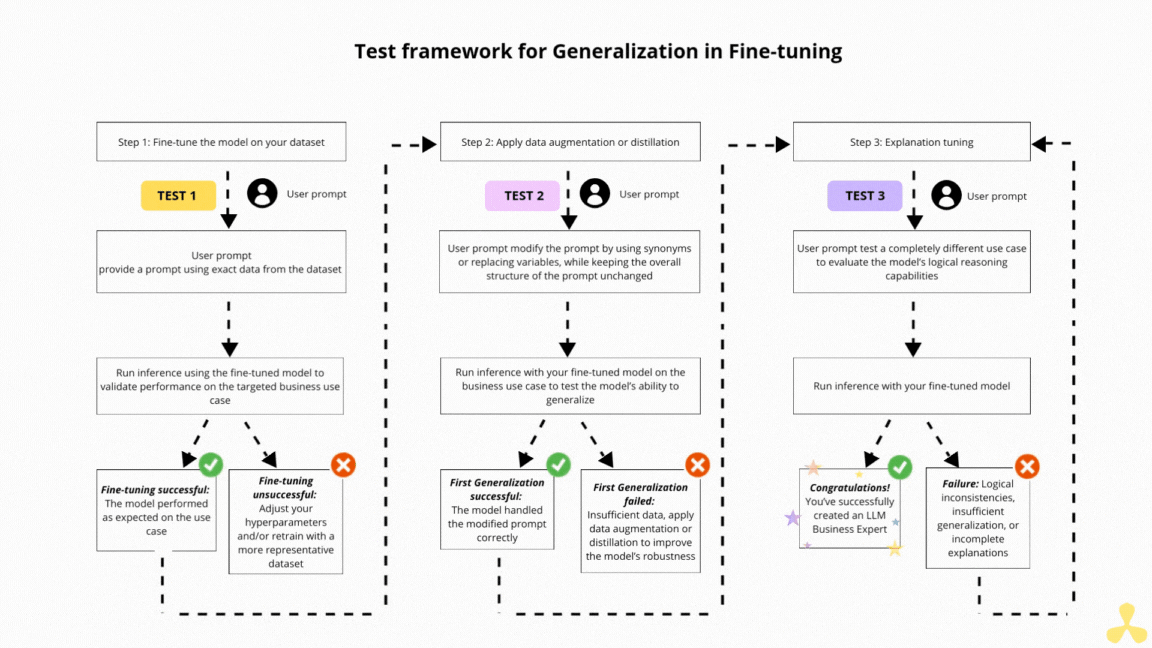
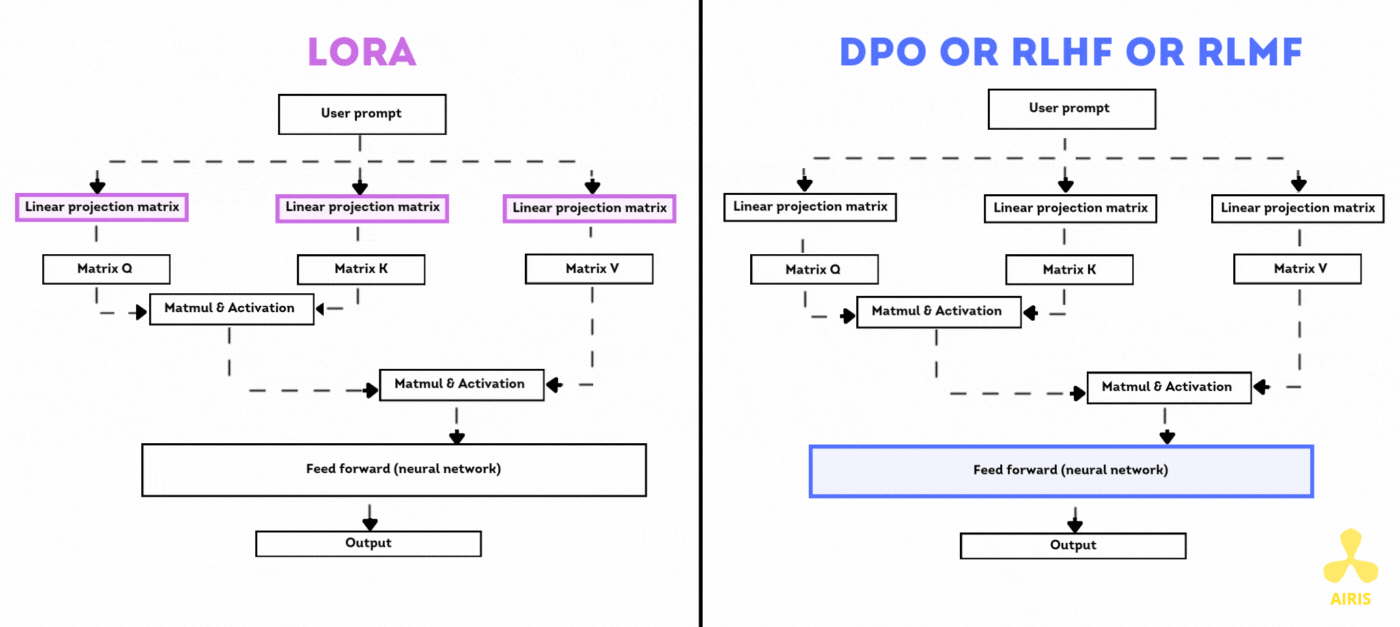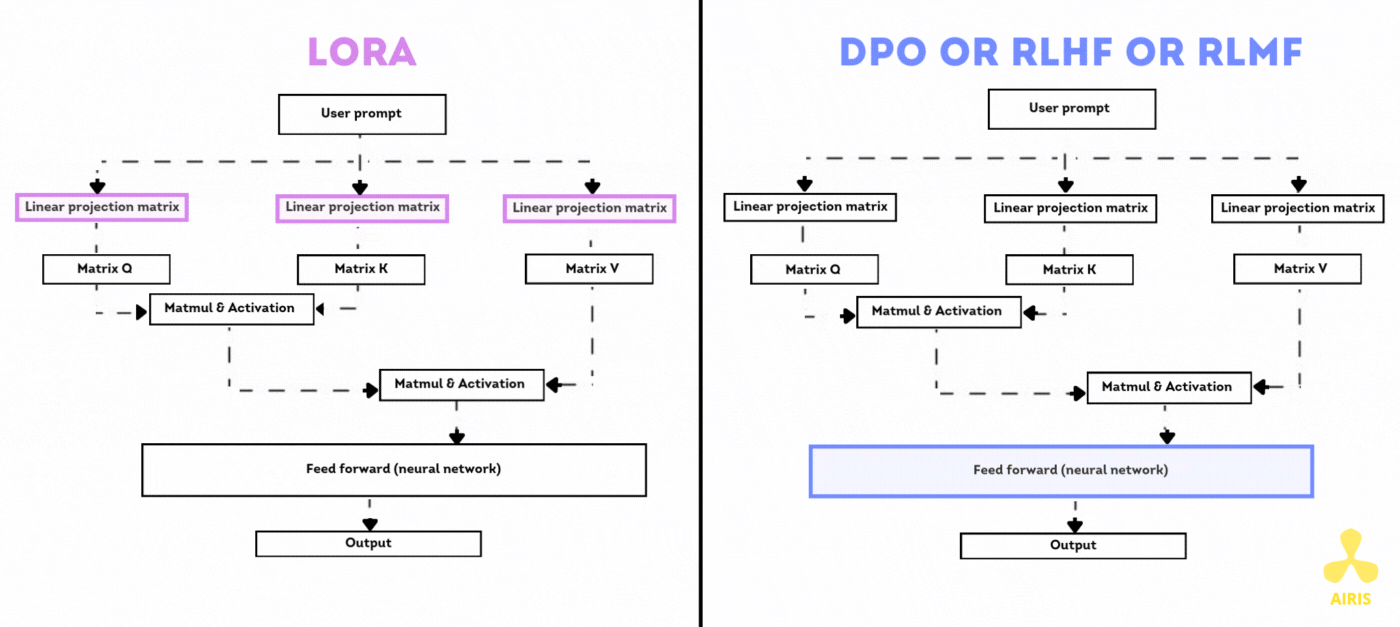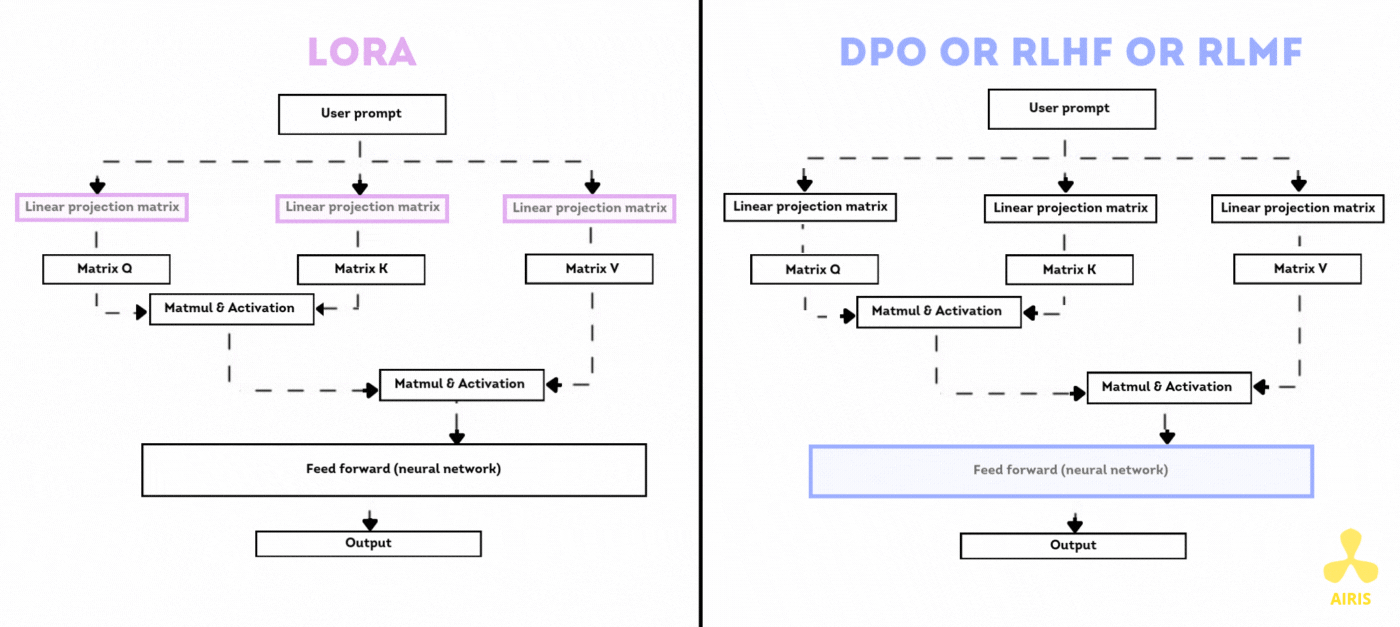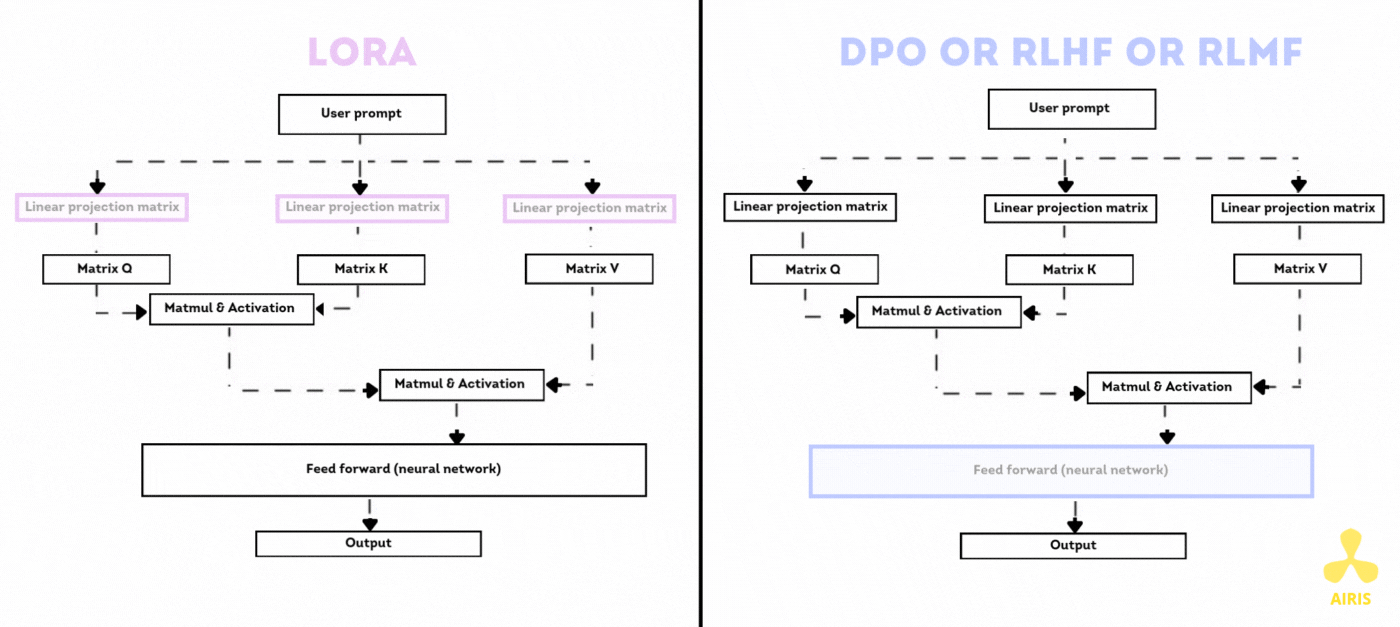
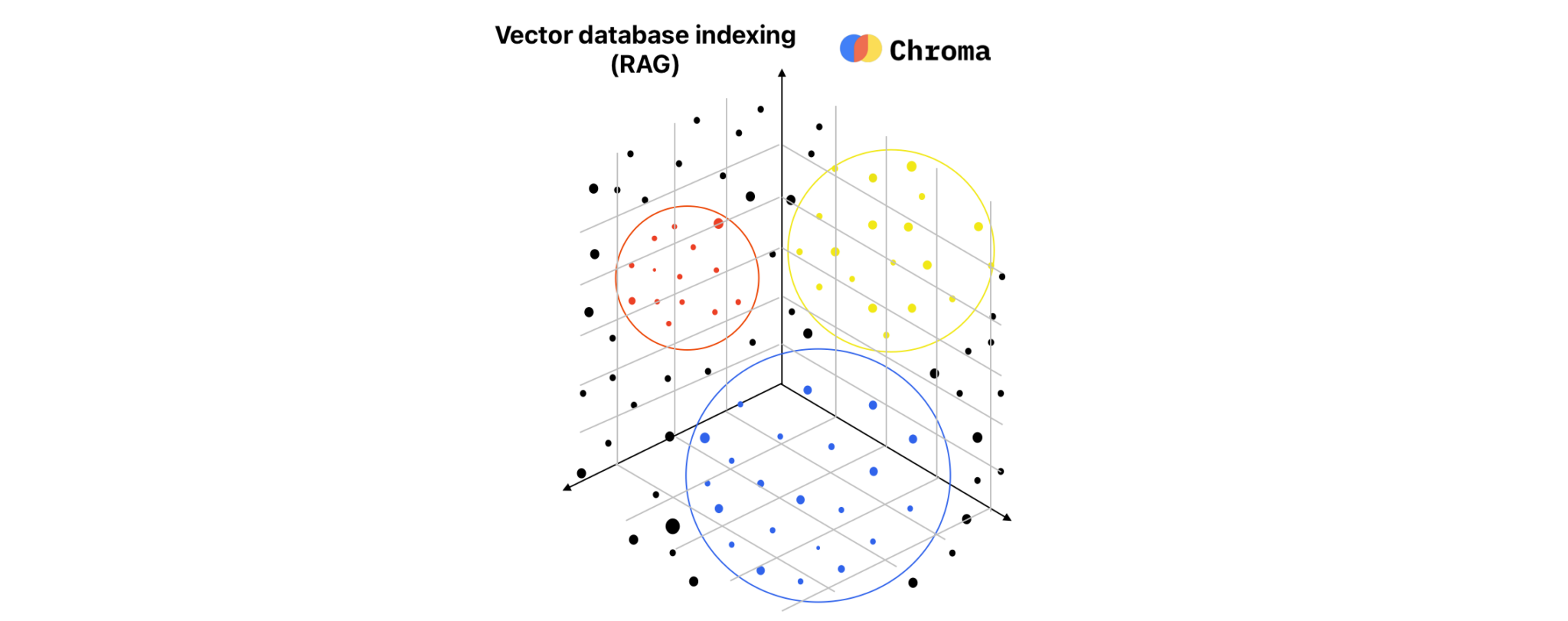
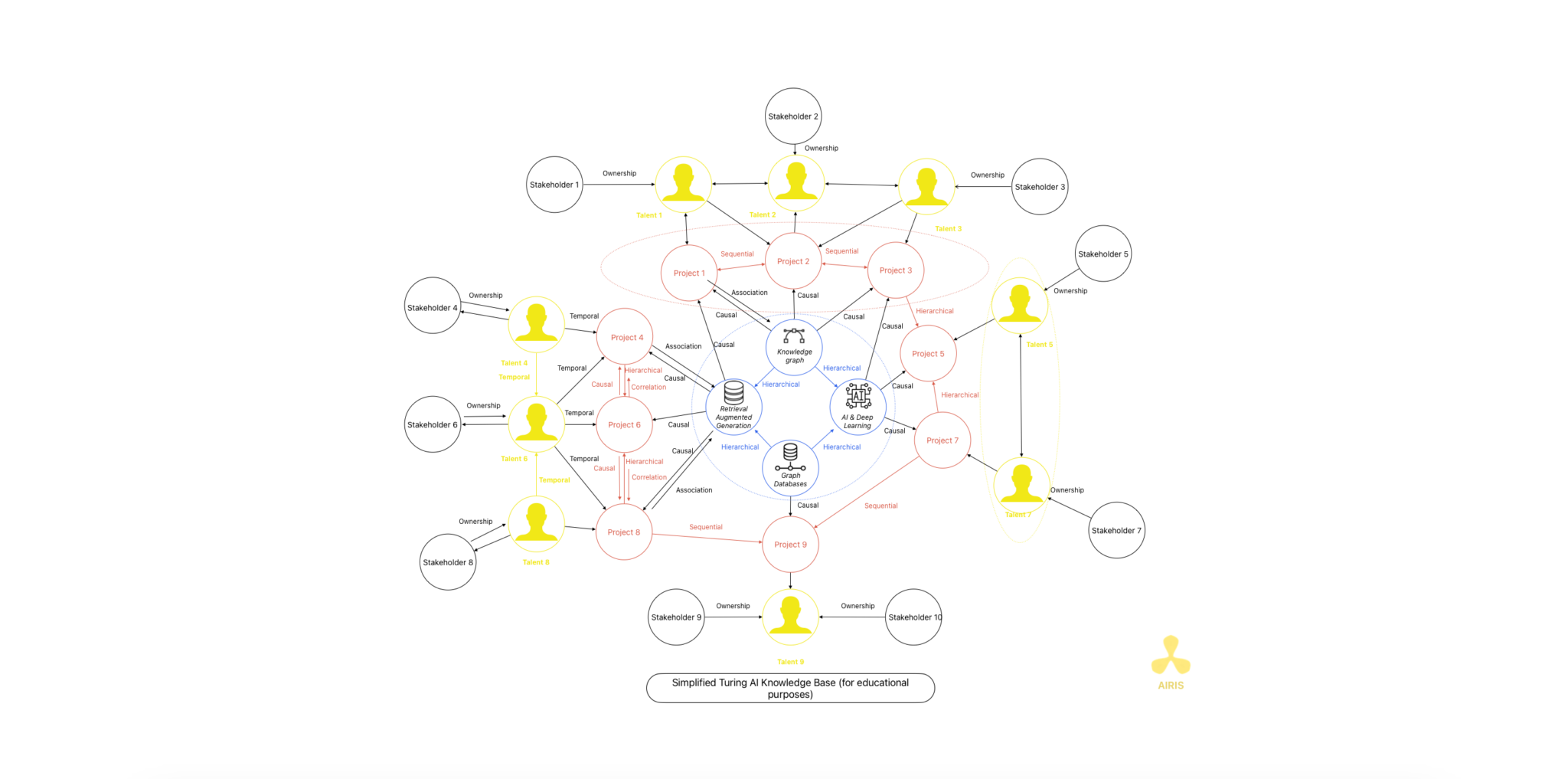
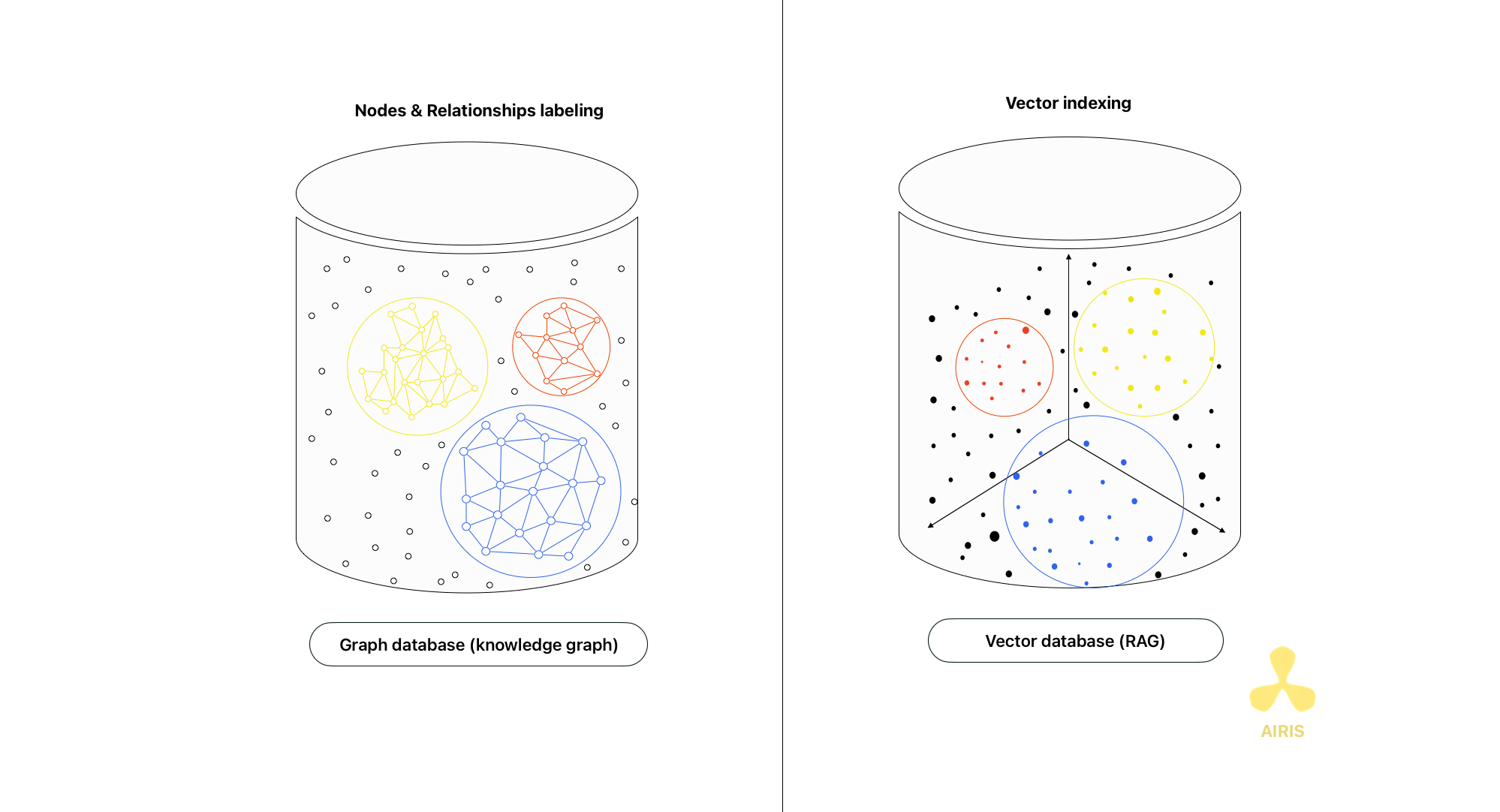
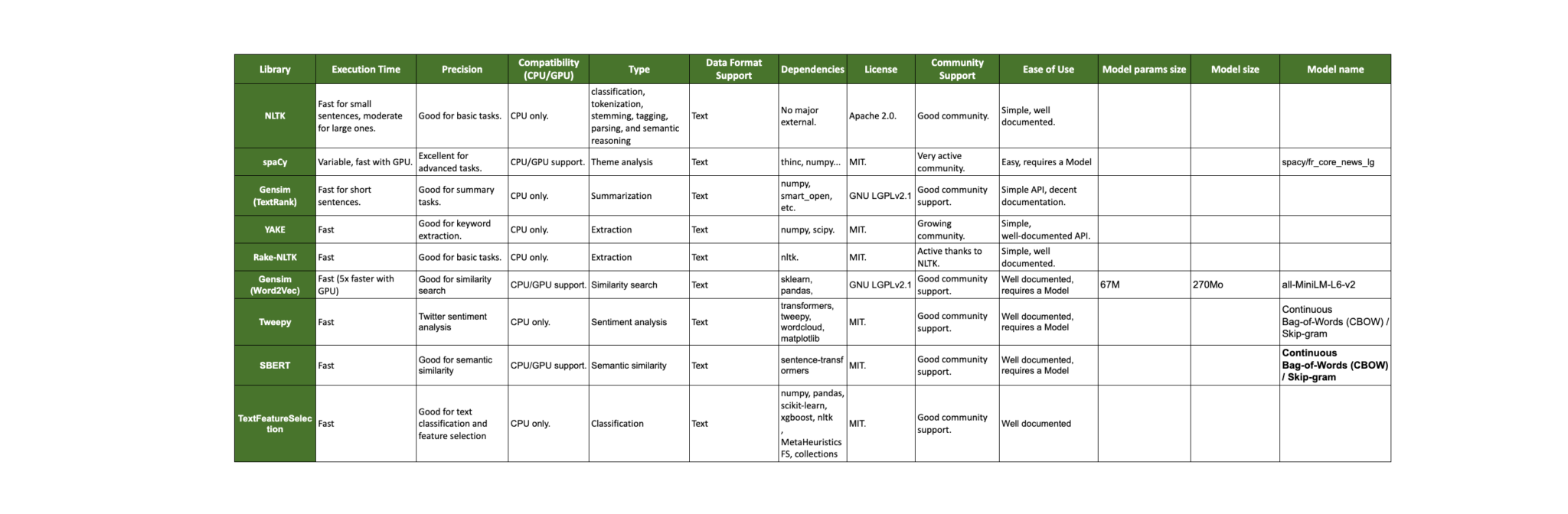
Base de données vectorielle avec Chroma DB et RAG Base de données vectorielle avec Chroma DB et RAG Read More »
Comprendre les concepts d’indexation et de clustering Comprendre les concepts d’indexation et de clustering Read More »
Qu’est-ce que le prompt dynamique et comment ça fonctionne ? Qu’est-ce que le prompt dynamique et comment ça fonctionne ? Read More »